![[KANANA429] Kanana-o 멀티모달 AI의 아키텍처와 서빙 구조](https://xnnnqymhqgwnvwuvbbrp.supabase.co/storage/v1/object/public/blog-images/thumbnails/1778320520390-snaphub_r5_6938.jpg________.jpg________.jpg)
국내 최초 텍스트·음성·이미지 통합 멀티모달 모델 Kanana-o의 모델 머징 개발 방법론, LMSPT 음성 토크나이저, 스트리밍 서빙 최적화, 그리고 API 직접 호출로 수집한 실측 데이터(48청크·TTFA 3.477초)를 분석합니다.
 Tristan2026.03.24Kanana-o카카오클라우드멀티모달AI모델머징MoE오디오스트리밍PCM한국어AI
Tristan2026.03.24Kanana-o카카오클라우드멀티모달AI모델머징MoE오디오스트리밍PCM한국어AI개요

Kanana-o는 카카오가 개발한 국내 최초 텍스트·음성·이미지 통합 멀티모달 언어모델입니다. 2025년 5월 1일 첫 공개됐으며, 어떤 조합의 입력(텍스트, 음성, 이미지, 또는 혼합)이 들어오더라도 처리하고 텍스트 또는 자연스러운 음성으로 응답합니다.
위 오디오 플레이어에서 Kanana-o API로 생성한 한국어 구연동화를 직접 들을 수 있습니다.
1. Kanana 모델 패밀리
카카오는 Kanana 브랜드 아래 용도별로 분화된 모델 시리즈를 운영합니다.
| 모델명 | 파라미터 | 유형 | 주요 특징 |
|---|---|---|---|
| Kanana-Nano-2.1B | 2.1B | Dense LLM | 경량, Embedding 지원 |
| Kanana-1.5-8B | 8B | Dense LLM | LLaMA 기반, Apache 2.0 |
| Kanana-1.5-15.7B-A3B | 15.7B (활성 3B) | MoE LLM | 한국 최초 오픈소스 MoE |
| Kanana-1.5-v-3B | 3.67B | Vision-LM | 이미지+텍스트, HF 다운로드 1위 |
| Kanana-1.5-o (Kanana-o) | 9.8B | Omni | 텍스트+음성+이미지 통합 |
| Kanana-2-30B-A3B | 30B (활성 3B) | MoE LLM | MLA 어텐션, 6개 언어 |
Kanana-2 아키텍처 (최신 세대)
Kanana-2는 DeepSeek-V3와 유사한 MLA(Multi-head Latent Attention) 어텐션 구조를 채택한 MoE 모델입니다.
| 항목 | 값 |
|---|---|
| 총 파라미터 | 30B |
| 활성 파라미터 | 3B (추론 시 약 10% 사용) |
| 레이어 수 | 48개 (Dense 1개 포함) |
| Expert 수 | 128개 (토큰당 6개 선택 + 공유 2개) |
| 어휘 크기 | 128,256 토큰 |
| 컨텍스트 길이 | 32,768 (YaRN으로 128K 확장) |
| 한국어 토크나이저 효율 | 이전 세대 대비 30% 향상 |
| 지원 언어 | 한국어·영어·일본어·중국어·태국어·베트남어 |
2. 사전학습 방법론
Kanana LLM 시리즈(arXiv:2502.18934)의 사전학습에는 세 가지 핵심 기법이 적용됩니다.
Staged Pre-training (단계적 사전학습)
총 3조(3T) 토큰을 두 단계로 나누어 학습합니다.
| 단계 | 토큰 수 | 목적 |
|---|---|---|
| Stage 1 | 2.7조 토큰 | 넓은 범위의 일반 지식 습득 |
| Stage 2 | 3,000억 토큰 | 고품질 데이터 집중 학습 |
Depth Up-Scaling (DUS)
기존 모델(8B, 26.8B)에 레이어를 추가하는 방식으로 더 큰 모델을 만듭니다. 처음부터 학습하는 것 대비 연산 비용을 11.06% 절감합니다.
[기존 모델 레이어 복제] 8B dense → (레이어 추가) → 9.8B / 32.5B 26.8B → (레이어 추가) → 더 큰 모델
Pruning & Distillation (가지치기 + 지식 증류)
2.1B Nano 모델은 처음부터 학습하지 않고 큰 모델로부터 증류해 생성합니다.
| 방법 | 필요 토큰 | 상대 비용 |
|---|---|---|
| 처음부터 학습 | 3조 토큰 | 100% |
| Pruning + Distillation | 0.3조 토큰 | 10% |
사전학습 벤치마크 (Base 모델)
| 모델 | MMLU | KMMLU | HAE-RAE | HumanEval | GSM8K |
|---|---|---|---|---|---|
| Kanana-Nano 2.1B | 54.83 | 44.80 | 77.09 | 31.10 | 46.32 |
| Kanana-Essence 9.8B | 67.61 | 50.57 | 84.97 | 40.24 | 63.61 |
| Kanana-Flag 32.5B | 77.68 | 62.10 | 90.47 | 51.22 | 70.05 |
| Kanana-2 30B-A3B | 75.44 | 62.15 | 88.73 | 75.29 | 82.71 |
Kanana-2는 30B 총 파라미터임에도 활성 파라미터가 3B에 불과해, 32.5B Dense 대비 추론 비용을 대폭 절감하면서 KMMLU 성능은 동등 이상입니다.
3. Kanana-o 개발 방법론: 모델 머징
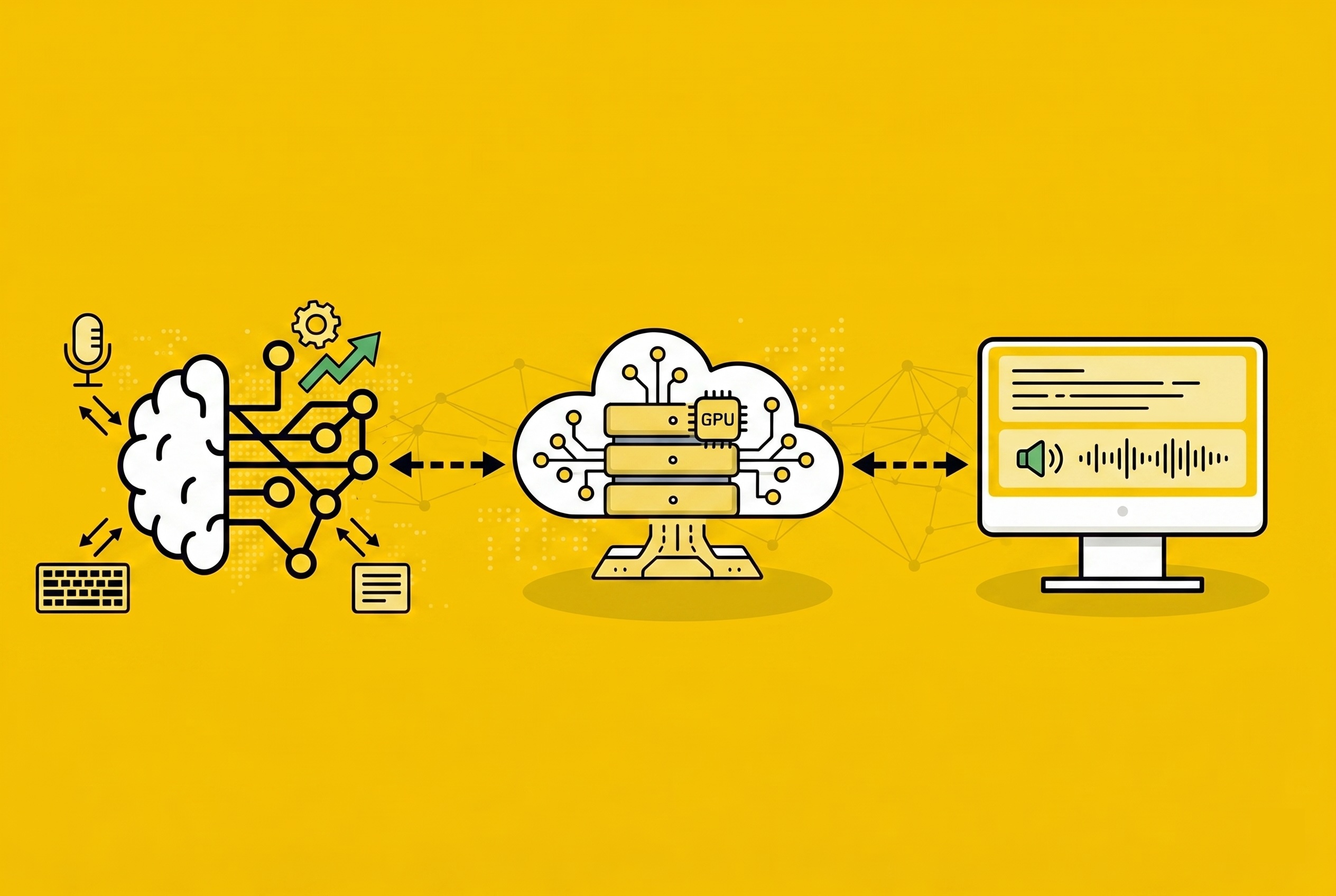
Kanana-o는 처음부터 멀티모달로 학습하는 대신, 전문화된 두 모델을 모델 머징(Model Merging)으로 통합합니다.
Kanana-v (이미지 전문)
│ 정제된 이미지-텍스트 쌍 데이터로 사전학습
│ 네이티브 레졸루션 이미지 처리
│
├──── 모델 머징 ────┐
│ ▼
Kanana-a (오디오 전문) Kanana-o (통합)
│ TTS 모델로 │ 공동 파인튜닝
│ 음성 데이터 생성 │ (Joint Training)
│ LMSPT 토크나이저 │이 접근법의 핵심 장점은 각 모달리티 전문성을 보존하면서 통합 능력을 빠르게 확보할 수 있다는 것입니다.
포스트 트레이닝
| 기법 | 적용 대상 | 효과 |
|---|---|---|
| SFT | 요약·감정 해석·오류 수정·번역 등 5개 도메인 | 지시이행 능력 향상 |
| DPO | 고품질 음성 데이터 | 억양·감정·호흡 정교화 |
| 팟캐스트 데이터셋 | 멀티턴 대화 | 자연스러운 다중 턴 확보 |
4. 음성 특화 기술
LMSPT (Language Model Speech Processing Tokenizer)
카카오가 자체 개발한 음성 토크나이저입니다. 음성 신호를 LLM이 처리할 수 있는 이산 토큰으로 변환하며, 기존 방식 대비 음성 생성 속도를 약 6배 향상시켰습니다.
한국어 특화 기능
| 기능 | 설명 |
|---|---|
| 감정 인식 | 억양·발화 패턴·음성 떨림으로 감정 상태 분석 |
| 방언 처리 | 제주도·경상도 방언 인식 후 표준어 변환 |
| 배경음 처리 | 잡음 환경에서도 음성 인식 |
| 감정 표현 | 기쁨·슬픔·분노·공포 등 상황별 음성 출력 |
| 실시간 통역 | 언어 간 실시간 음성 통역 |
성능 벤치마크
| 평가 항목 | Kanana-o | GPT-4o | Gemini 2.5 Pro |
|---|---|---|---|
| 영어 음성 지시 수행 | 77.54 | 87.12 | 90.41 |
| 한국어 음성 인식 | 월등히 우수 | 중간 | 중간 |
| 한국어 음성 합성 | 월등히 우수 | 중간 | 중간 |
| 한국어 감정 인식 | 큰 격차로 우위 | 낮음 | 낮음 |
| 영어 감정 인식 | 큰 격차로 우위 | 낮음 | 낮음 |
영어 절대 성능은 GPT-4o에 못 미치지만, 한국어 음성 관련 태스크에서는 글로벌 모델들을 현저히 앞서는 성능을 보입니다.
5. 서빙 아키텍처
카카오 기술 블로그 posts/821(hulk.5, steve.ai)에서 공개한 Kanana-o 프로덕션 서빙 최적화 내용입니다.
스트리밍 TTS 파이프라인
기존 방식은 응답 전체를 생성한 뒤 TTS로 변환했습니다. Kanana-o는 생성과 동시에 스트리밍 합성합니다.
| 구분 | 기존 방식 | 스트리밍 방식 |
|---|---|---|
| 흐름 | LLM 전체 생성 → TTS 변환 | LLM 생성 + TTS 병렬 스트리밍 |
| TTFA | 1.5초 | 0.5초 (3배 단축) |
| 체감 응답성 | 낮음 | 높음 |
[기존] STT → LLM (완료) → TTS (완료) → 재생
[신규] STT → LLM (스트림) ─┬─▶ TTS (스트림) ─▶ 재생
└─▶ 텍스트 출력실측: API 직접 호출 결과
이번 실험에서 Kanana-o API를 직접 호출해 한국어 구연동화(~1,200자)를 생성한 결과입니다.
| 항목 | 측정값 |
|---|---|
| 총 재생 시간 | 194.4초 (3분 14.4초) |
| 파일 크기 | 8.90 MB (WAV, 무손실) |
| 스트리밍 청크 수 | 48개 |
| TTFA (첫 청크) | 3.477초 |
| 정규 청크 길이 | 4.011초 고정 (46개 연속 동일) |
| 마지막 청크 | 6.421초 (잔여 버퍼 flush) |
| 발화 속도 | 370자/분 (자연 발화 300~400자/분 범위) |
고정 버퍼 크기 역산
46개 청크가 4.011초로 완전히 동일하다는 점에서 내부 버퍼 크기를 역산할 수 있습니다.
sample_rate = 24_000 # Hz
chunk_length = 4.011 # 초
frames = int(sample_rate * chunk_length) # 96,264 프레임
bytes_per_frame = 2 # 16-bit = 2 bytes
buffer_size = frames * bytes_per_frame # 192,528 bytes ≈ 188 KB첫 청크(3.477초)가 정규 청크보다 짧은 것은 TTFA를 최소화하기 위한 조기 flush(early flush) 전략입니다.
6. API 구조
엔드포인트
| 항목 | 값 |
|---|---|
| Base URL | https://kanana-o.a2s-endpoint.kr-central-2.kakaocloud.com/v1 |
| SDK 호환 | OpenAI Python SDK (base_url 교체만으로 동작) |
| 프로토콜 | HTTPS + SSE (Server-Sent Events) 스트리밍 |
텍스트 → 오디오 생성
from openai import OpenAI
import base64, wave, os
client = OpenAI(
base_url="https://kanana-o.a2s-endpoint.kr-central-2.kakaocloud.com/v1",
api_key="YOUR_KANANA_API_KEY",
)
response = client.chat.completions.create(
model="kanana-o",
messages=[{
"role": "user",
"content": [{"type": "text", "text": "구연동화 형식으로 읽어주세요: ..."}],
}],
modalities=["text", "audio"], # 오디오 출력 활성화
stream=True,
)
os.makedirs("chunks", exist_ok=True)
chunk_files, cnt = [], 0
for chunk in response:
delta = chunk.model_dump()["choices"][0].get("delta", {})
audio = delta.get("audio")
b64 = (audio or {}).get("data") if isinstance(audio, dict) else audio
if not b64:
continue
pcm = base64.b64decode(b64)
path = f"chunks/{cnt:04d}.wav"
with wave.open(path, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2) # 16-bit PCM
wf.setframerate(24000)
wf.writeframes(pcm)
chunk_files.append(path)
cnt += 1
print(f"생성 완료: {cnt}개 청크")이미지 + 오디오 복합 입력
def to_b64(path: str) -> str:
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="kanana-o",
messages=[{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": to_b64("image.jpg")}},
{"type": "input_audio", "input_audio": {"data": to_b64("audio.wav"), "format": "wav"}},
{"type": "text", "text": "이 이미지에 대해 음성으로 설명해줘"},
],
}],
modalities=["text", "audio"],
stream=True,
)Delta 응답 구조
SSE 이벤트마다 텍스트와 오디오가 독립 채널로 실려옵니다.
{
"choices": [{
"delta": {
"content": "옛날 옛적...",
"audio": {
"data": "<base64-PCM-chunk>"
}
}
}]
}7. 오디오 포맷
PCM 스펙
| 항목 | 값 | 비고 |
|---|---|---|
| 인코딩 | 16-bit signed PCM | Little-endian |
| 채널 | 1 (Mono) | 음성 전용 최적화 |
| 샘플레이트 | 24,000 Hz | 음성 대역 완전 커버 |
| 비트레이트 | 384 kbps | 무손실 |
포맷별 파일 크기 비교 (동일 콘텐츠 기준)
| 포맷 | 비트레이트 | 194초 기준 크기 |
|---|---|---|
| CD 품질 WAV (스테레오 44.1kHz) | 1,411 kbps | 34.3 MB |
| 방송 음성 WAV (Mono 32kHz) | 512 kbps | 12.5 MB |
| Kanana-o 출력 (Mono 24kHz) | 384 kbps | 8.9 MB |
| MP3 128kbps | 128 kbps | 3.1 MB |
Base64 전송 오버헤드
SSE를 통해 전송되는 PCM은 Base64로 인코딩되어 전송 크기가 증가합니다.
청크 RAW PCM : 188 KB Base64 인코딩 (전송) : 251 KB (+33%) 클라이언트 디코딩 후 : 188 KB (원복)
8. 로드맵
단기 (Kanana-o 업데이트)
- Full-duplex (동시 대화): 사용자와 AI가 동시에 발화하는 기능
- 실시간 사운드스케이프 생성: 배경음 실시간 합성
중기 (Kanana-v-embedding)
멀티모달 임베딩 모델 확장.
| 현재 | 계획 |
|---|---|
| 텍스트 + 이미지 | 텍스트 + 이미지 + 비디오 |
| — | 텍스트 + 이미지 + 오디오 |
장기 (Kanana-2.5)
카카오 CEO 정신아가 2026년 1분기 실적 발표에서 언급한 차기 모델.
- 파라미터: 150B
- 목적: AI 에이전트 플랫폼 전용
Kanana-2 Instruct 벤치마크 (현재 세대 최상위)
| 벤치마크 | 점수 | 비고 |
|---|---|---|
| MT-Bench | 8.42 | GPT-4 수준 |
| KoMT-Bench | 8.24 | 한국어 대화 |
| IFEval | 84.47% | 지시 이행 |
| BFCL-v3 (Tool Calling) | 74.30% | 에이전트 기능 |
| HumanEval+ | 79.88% | 코드 생성 |
| MATH | 86.26% | 수학 추론 |
| RULER-32K | 88.63% | 장문 컨텍스트 |
참고 자료
AI 솔루션이 필요하신가요?
cortexys.ai에서 맞춤 AI 개발 서비스를 확인하세요.
![[논문] KoALa 한국어 음성 AI를 제대로 평가하는 최초의 종합 벤치마크](https://arxiv.org/html/2604.19782v1/images/K-Bench-A.png)
![[논문] 데이터가 적을 때 이미지 AI를 제대로 훈련하는 법 - APT기법](https://arxiv.org/html/2507.02687v1/x1.png)