참조 이미지가 몇 장 없을 때 디퓨전 모델이 과적합되는 문제를 세 가지 전략으로 해결한다. 타임스텝별 실시간 과적합 감지(ATA), 특성 맵 통계 안정화(RS), 크로스 어텐션 정렬(AA)로 FID를 21% 개선하고 사용자 선호도 56%를 달성했다.
 Cortexys2026.05.01Diffusion ModelPersonalizationDreamBoothSDXLLoRA논문리뷰
Cortexys2026.05.01Diffusion ModelPersonalizationDreamBoothSDXLLoRA논문리뷰데이터가 적을 때 이미지 AI를 제대로 훈련하는 법: APT의 세 가지 전략
논문: "APT: Adaptive Personalized Training for Diffusion Models with Limited Data" 저자: JungWoo Chae*, Jiyoon Kim* (공동 1저자), JaeWoong Choi, Kyungyul Kim — LG CNS AI Research; Sangheum Hwang — Seoul National University of Science and Technology arXiv: 2507.02687v1
문제: 이미지가 몇 장 없을 때 AI가 "외워버린다"
Stable Diffusion, SDXL 같은 이미지 생성 AI를 특정 개념(나만의 캐릭터, 제품 사진, 반려동물)에 맞게 개인화(personalization)하는 것은 매력적인 기술이다. DreamBooth, LoRA 같은 방법으로 몇 장의 참조 이미지를 파인튜닝하면 "내 스타일"을 학습시킬 수 있다.
그런데 문제가 있다. 이미지가 적으면 모델이 외워버린다(overfitting).
백팩 이미지 5장으로 파인튜닝한다고 해보자. "사람이 백팩을 메고 있는 장면"을 생성하라고 해도 모델은 배경 없이 백팩만 뚝 떨어진 이미지를 생성한다. 파인튜닝 전 SDXL은 자연스럽게 "백팩 = 사람이 메는 것"이라는 상식을 알고 있었는데, 과적합으로 그 사전 지식(prior knowledge)이 사라져버린 것이다.
이 논문의 APT(Adaptive Personalized Training)는 그 문제를 세 가지 전략으로 동시에 해결한다.
과적합이 타임스텝마다 다르게 나타난다
APT의 핵심 통찰은 단순하다: 확산 모델의 과적합은 타임스텝에 따라 다르게 발생한다.
확산 모델은 1000개의 노이즈 제거 타임스텝을 거친다. 초기 타임스텝(고노이즈)은 전체적인 레이아웃과 구도를 결정하고, 후기 타임스텝(저노이즈)은 세부 질감과 디테일을 담당한다. 과적합도 이 패턴을 따른다 — 질감 암기(texture memorization)를 담당하는 후기 타임스텝에서 과적합이 더 빠르고 심하게 발생한다.
또한 어떤 데이터셋이냐에 따라 과적합 속도가 다르다. 백팩 데이터셋은 부츠 데이터셋보다 학습 말기 예측 노이즈 차이(ΔNoise)가 두 배 이상 크다. 고정된 정규화 강도로는 모든 상황에 대응할 수 없다.
APT의 구조: 세 가지 컴포넌트
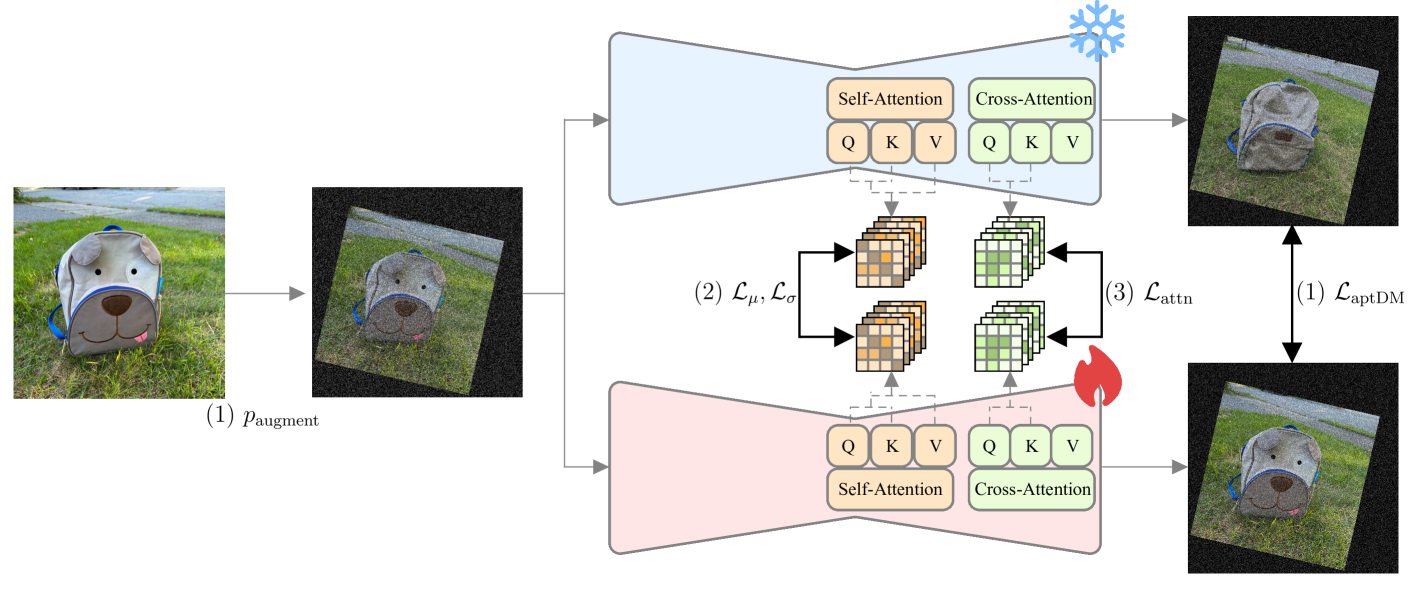
APT는 세 가지 컴포넌트를 동시에 적용한다. 구현은 SDXL 위에 Rank-32 LoRA(U-Net + 텍스트 인코더)를 사용하며, 단일 NVIDIA A100 GPU에서 학습한다.
컴포넌트 1: ATA — 과적합을 실시간으로 감지하고 대응한다
과적합 지표 (Overfitting Indicator)
파인튜닝 모델이 얼마나 과적합되었는지 실시간으로 측정하는 지표다. 사전학습된 원본 모델(φ)과 파인튜닝 중인 모델(θ)의 손실을 비교한다.
직관적으로 이해하기:
- 학습이 진행될수록 파인튜닝 모델의 손실()이 원본 모델()보다 낮아진다.
- 그 차이가 클수록 과적합이 심하다는 뜻이므로 가 1에 가까워진다.
- 1000개의 타임스텝을 10개 구간(B = 10 bins)으로 나눠 각각 독립적으로 계산한다.
- EMA(지수이동평균, )로 노이즈를 제거해 안정적인 신호를 만든다.
- 온도 파라미터 는 총 디퓨전 스텝 수(SDXL에서 1000)로 설정한다.
결과: 0(과적합 없음)에서 1(심각한 과적합)까지의 실시간 지표가 타임스텝 구간별로 생성된다.
적응적 데이터 증강
가 높아지면 확대/축소(1~3배), 회전(±15도) 등의 기하학적 변환을 더 높은 확률로 적용한다. 최대 확률은 . 모델이 특정 구도를 외울수록 더 다양한 구도로 학습시키는 것이다.
적응적 손실 가중치
과적합이 심한 타임스텝 구간의 학습 기여도를 줄인다. 이미 "외운" 영역의 학습을 약화시키고, 아직 덜 배운 영역에 집중하게 만드는 것이다.
컴포넌트 2: RS — 특성 맵의 통계를 안정화한다
U-Net의 업블록(Upblocks, 32×32와 64×64 해상도)에서 파인튜닝 모델과 원본 모델의 활성화 값을 비교해 정규화한다.
평균 정규화:
분산 정규화:
직관적으로 이해하기: 파인튜닝이 진행될수록 모델 내부의 특성 분포가 원본과 달라진다. 이것이 노이즈 제거 경로(denoising trajectory)가 원본 모델에서 멀어지는 원인이다. 평균과 분산을 맞추면 인스턴스 정규화(instance normalization)와 비슷한 효과로 내부 표현 공간이 안정화된다. RS 적용 시 피사체의 과도한 질감 복제가 줄어들고, 색감도 더 자연스러워지는 것이 확인된다.
구현 팁: LoRA는 forward pass 중 on/off 전환이 가능하므로, 사전학습 모델의 특성을 가져올 때 별도의 모델을 추가 로드할 필요가 없다. 중간 특성 값만 추가 메모리에 저장하면 된다.
컴포넌트 3: AA — 크로스 어텐션 맵을 정렬한다

크로스 어텐션 맵은 텍스트의 각 단어가 이미지의 어느 영역에 영향을 미치는지를 나타낸다. 위 그림을 보면 DreamBooth는 파인튜닝 후 개념 토큰뿐 아니라 모든 토큰의 어텐션 맵이 변한다. 이것이 텍스트 정렬이 깨지는 이유다.
설계상의 중요한 선택 두 가지:
-
헤드별이 아닌 합산 후 정렬: 각 어텐션 헤드를 개별적으로 맞추면 모델이 내부 역할 분배를 자유롭게 조정할 수 없다. 전체 헤드를 합산한 뒤 비교하면, 내부적으로 헤드가 재구성되더라도 전체 분포는 유지된다.
-
개념 토큰만이 아닌 전체 토큰 정렬: DreamBooth가 모든 토큰의 어텐션을 바꾼다는 관찰에서 출발해, APT는 전체 텍스트 토큰의 어텐션을 정렬한다.
전체 학습 목표
하이퍼파라미터:
- ,
- U-Net 학습률: , 텍스트 인코더 학습률:
- 배치 크기: 1, 옵티마이저: AdamW, CFG scale: 7.5
학습 이미지 캡션 생성 방식: GPT-4o에 다음 프롬프트를 사용해 캡션을 자동 생성한다: "주변 환경과 맥락을 중심으로 이미지를 설명하되, 중심 피사체는 최대한 단순하게 묘사하라." 개념 자체가 아닌 배경과 문맥을 학습하게 함으로써, 모델이 문맥 연상 능력(예: "백팩 → 사람이 메는 것")을 유지하도록 유도한다.
세 손실이 각각 다른 수준의 과적합을 억제한다: ATA는 공간적(spatial) 암기, RS는 특성 공간(feature space) 표현, AA는 의미적(semantic) 어텐션 분포를 대상으로 한다.
실험 결과
정성적 비교

DreamBooth는 백팩만 덩그러니 있는 이미지를 생성하지만, APT는 사람이 백팩을 메고 있는 자연스러운 장면을 생성한다. 프롬프트에 "사람"이 없어도 사전 지식이 유지되기 때문이다.

정량적 비교 (Table 1)
| 방법 | CLIP-T ↑ | HPSv2 ↑ | DINOv2 ↑ | FID ↓ | Precision ↑ | Recall ↑ | 사용자 선호 |
|---|---|---|---|---|---|---|---|
| SDXL (원본) | 0.666 | 0.295 | 0.625 | — | — | — | — |
| Custom Diffusion | 0.662 | 0.273 | 0.666 | 45.530 | 0.590 | 0.649 | — |
| DCO | 0.662 | 0.277 | 0.687 | 52.298 | 0.548 | 0.660 | 21.1% |
| DreamBooth | 0.661 | 0.272 | 0.681 | 53.130 | 0.565 | 0.608 | 22.8% |
| +ATA | 0.664 | 0.275 | 0.670 | 46.872 | 0.635 | 0.680 | — |
| +ATA+RS | 0.664 | 0.290 | 0.657 | 42.663 | 0.701 | 0.727 | — |
| +ATA+RS+AA (전체 APT) | 0.664 | 0.288 | 0.660 | 41.967 | 0.669 | 0.738 | 56.1% |
APT의 성과:
- FID: 53.1 → 41.9 (DreamBooth 대비 약 21% 개선)
- Recall: 0.608 → 0.738 (다양성 크게 향상)
- 사용자 선호: 56.1% (DreamBooth 22.8%, DCO 21.1% 압도)
- Precision: +RS 단계에서 0.701로 최고점을 찍고 +AA 이후 0.669로 소폭 감소 — AA가 다양한 어텐션 분포를 허용하면서 다양성(Recall)이 늘어나는 대신 일부 정밀도를 교환한다.
DINOv2는 왜 살짝 낮을까? DINOv2는 참조 이미지와의 시각적 유사도를 측정한다. 과적합이 줄면 개념을 조금 더 유연하게 표현하므로 이 점수가 약간 낮아진다. 논문은 이를 합리적인 트레이드오프로 받아들인다.
컴포넌트별 기여도 분석

| 구성 | FID ↓ | Precision ↑ | Recall ↑ | HPSv2 ↑ | 변화 |
|---|---|---|---|---|---|
| DreamBooth (기준) | 53.130 | 0.565 | 0.608 | 0.272 | — |
| +ATA | 46.872 | 0.635 | 0.680 | 0.275 | FID −6.3, Recall +0.072 |
| +ATA+RS | 42.663 | 0.701 | 0.727 | 0.290 | FID −4.2, Precision +0.066 |
| +ATA+RS+AA | 41.967 | 0.669 | 0.738 | 0.288 | FID −0.7, Recall +0.011 |
각 컴포넌트가 명확하게 기여한다:
- ATA: 레이아웃 암기를 억제 — FID를 6.3 낮추고 Recall +0.072
- RS: 특성 분포 안정화로 Precision 크게 향상, HPSv2 +0.015 (시각적 품질 향상)
- AA: 의미적 일관성 보존으로 Recall 추가 향상. Precision은 소폭 감소하지만 다양성과 교환

과적합 지표의 실제 동작
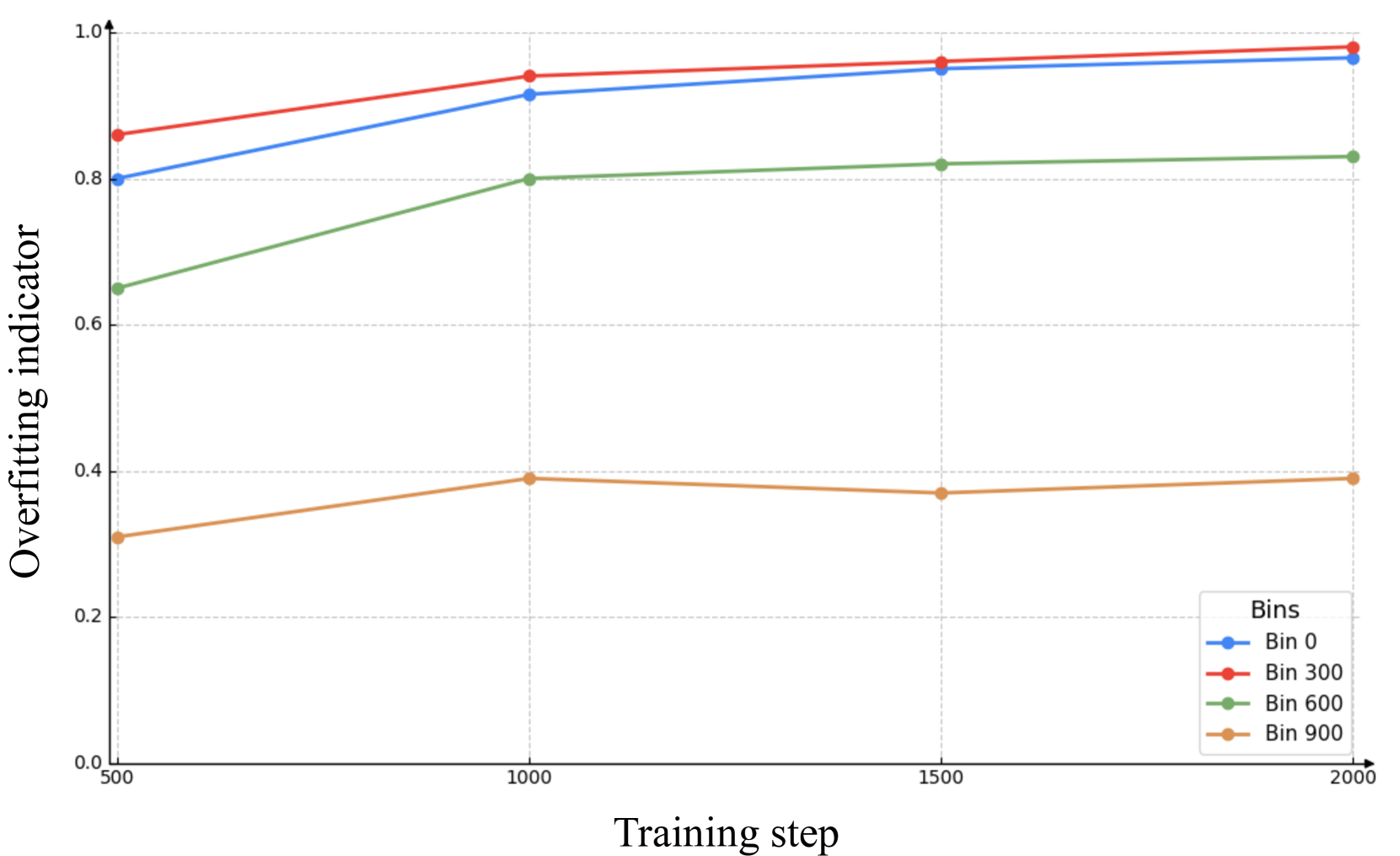

위 두 그림이 APT의 설계 근거를 명확히 보여준다. 백팩 데이터셋은 부츠 데이터셋보다 ΔNoise가 학습 말기에 두 배 이상 크게 발생한다. 타임스텝 구간별로도 후기 구간(저노이즈)에서 과적합이 먼저, 더 심하게 발생한다. 고정된 정규화 강도로는 모든 상황에 대응할 수 없으며, 실시간으로 감지하고 적응하는 것이 필수적이다.
추가 비교 실험



APT는 SDXL뿐 아니라 Stable Diffusion v2.1에서도 NeTI, ViCo, OFT, AttnDreamBooth 등 기존 방법들을 앞선다. SD v2.1에서는 과적합이 SDXL보다 빠르게 수렴하므로 γ 계산 시 온도 파라미터를 대신 으로 조정한다 — 이것 하나만 바꾸면 다른 아키텍처에도 그대로 적용된다.
사용자 연구

20명의 참가자, 20개의 프롬프트로 진행된 사용자 연구에서 APT가 56.1%의 선호도를 얻었다. 평가 기준은 세 가지: ① 프롬프트 텍스트 정렬, ② 참조 이미지와의 정체성 유사도, ③ SDXL 원본 대비 사전 지식 보존. SDXL 원본 이미지를 기준점으로 제공하여 "사전 지식 보존" 항목을 공정하게 평가했다.
한계와 미래 방향
- 정체성 보존 트레이드오프: 과적합을 줄이면 DINOv2(참조 유사도)가 소폭 하락한다.
- 계산 비용: RS와 AA 손실 계산을 위해 추가 순전파(forward pass)가 필요해 메모리와 연산량이 늘어난다. 향후 일부 레이어/해상도만 선택적으로 계산하는 방식으로 경량화 가능하다.
- 하이퍼파라미터 민감도: 특히 는 개념마다 조정이 필요할 수 있다.
- 통합 정규화 항: RS와 AA를 하나의 통합 손실로 결합하면 하이퍼파라미터 복잡도를 낮출 수 있다는 방향도 제시된다.
결론
APT는 이미지 개인화 파인튜닝의 과적합 문제를 세 가지 상호보완적인 방법으로 해결한다:
- ATA — 타임스텝별 실시간 과적합 감지 후 증강 확률과 손실 가중치를 동적으로 조정
- RS — U-Net 특성 맵의 평균과 분산을 정규화해 노이즈 제거 경로를 안정화
- AA — 전체 크로스 어텐션 분포를 정렬해 텍스트 정렬과 사전 지식을 보존
결과적으로 FID 21% 개선, 다양성(Recall) 21% 향상, 그리고 사용자 선호도 56%로 기존 방법들을 압도했다. 아키텍처 독립적으로 SDXL과 SD v2.1 모두에서 검증되었으며, SD v2.1 적용 시 단 하나의 하이퍼파라미터() 조정만으로 작동한다. "데이터가 적을 때 AI를 잘 훈련하는 법"이라는 실용적 문제에 체계적이고 이론적으로 탄탄한 답을 제시한 논문이다.
AI 솔루션이 필요하신가요?
cortexys.ai에서 맞춤 AI 개발 서비스를 확인하세요.
![[논문] KoALa 한국어 음성 AI를 제대로 평가하는 최초의 종합 벤치마크](https://arxiv.org/html/2604.19782v1/images/K-Bench-A.png)
![[KANANA429] Kanana-o 멀티모달 AI의 아키텍처와 서빙 구조](https://xnnnqymhqgwnvwuvbbrp.supabase.co/storage/v1/object/public/blog-images/thumbnails/1778320520390-snaphub_r5_6938.jpg________.jpg________.jpg)