Samsung AI Lab이 발표한 Tiny Recursive Model(TRM)은 7M 파라미터 단일 네트워크로 ARC-AGI에서 Gemini 2.5 Pro를 앞서는 성능을 달성했다. 완전 역전파·단일 네트워크·EMA 세 가지 단순화가 HRM 대비 30%p 이상의 성능 향상을 이끌어낸 원리를 분석한다.
 Cortexys2026.05.09TRMHRMARC-AGI재귀 추론소형 모델추론 능력Samsung AI
Cortexys2026.05.09TRMHRMARC-AGI재귀 추론소형 모델추론 능력Samsung AI거대한 AI 모델이 풀지 못하는 문제를 700만 개 파라미터짜리 초소형 네트워크가 푼다면 어떨까. Gemini 2.5 Pro보다 10,000배 작은 모델이 ARC-AGI 벤치마크에서 더 높은 점수를 기록했다. Samsung AI Lab Montreal의 Alexia Jolicoeur-Martineau가 발표한 Tiny Recursive Model(TRM) 이야기다.
배경: 추론은 왜 어려운가.
대형 언어 모델(LLM)은 지식과 언어 생성에서 탁월하지만, **구조적 추론(hard reasoning)**에서는 종종 실패한다. Chain-of-Thought, 테스트 시 추가 연산 등 다양한 기법이 제안됐지만, 복잡한 퍼즐이나 논리 과제에서 한계는 분명하다.
이 한계를 극복하려는 시도 중 하나가 **Hierarchical Reasoning Model(HRM)**이다. HRM은 두 개의 순환 네트워크를 계층적으로 구성해 반복적 추론을 구현했다. TRM은 이 HRM을 출발점으로 삼되, 복잡성을 과감히 제거하며 오히려 성능을 높였다.
HRM의 구조와 한계
HRM은 네 가지 구성요소로 이루어진다.
- 입력 임베딩: 문제를 벡터 공간으로 변환.
- 저수준 순환 네트워크 f_L: 세부 추론 과정을 담당하는 잠재 특징 z_L 업데이트.
- 고수준 순환 네트워크 f_H: 현재 해답 상태를 나타내는 잠재 특징 z_H 업데이트.
- 출력 헤드: 최종 예측 생성.
이 두 네트워크는 각각 4레이어 트랜스포머로 구성되고, RMSNorm·Rotary Embedding·SwiGLU 활성화를 사용한다. 역전파는 전체 재귀 단계 중 일부에만 적용하고, Q-learning 기반 **Adaptive Computational Time(ACT)**으로 조기 종료를 결정한다.
논문은 HRM의 세 가지 구조적 문제를 지적한다.
1. 고정점 수렴 가정의 취약성
HRM은 암시적 함수 정리(IFT)를 근거로 전체 재귀 6단계 중 2단계에만 그래디언트를 적용한다. 그러나 실제로는 z_H 잔차가 0으로 수렴하지 않고, z_L도 수렴까지 많은 사이클이 필요하다. 불과 4단계 재귀만으로는 고정점에 도달했다고 가정하기 어렵다.
2. ACT의 비효율성
기존 ACT는 continue-loss 계산을 위해 최적화 단계마다 추가 순전파가 필요하다. 사실상 연산량이 두 배로 늘어나는 셈이다.
3. 생물학적 해석의 모호성
계층적 구조를 뇌의 처리 주파수 차이로 설명하지만, 이 논리는 과학적으로 불분명하다. 어떤 아키텍처 요소가 실제 성능을 이끄는지 파악하기 어렵다.
TRM: 단순화로 성능을 높이다.
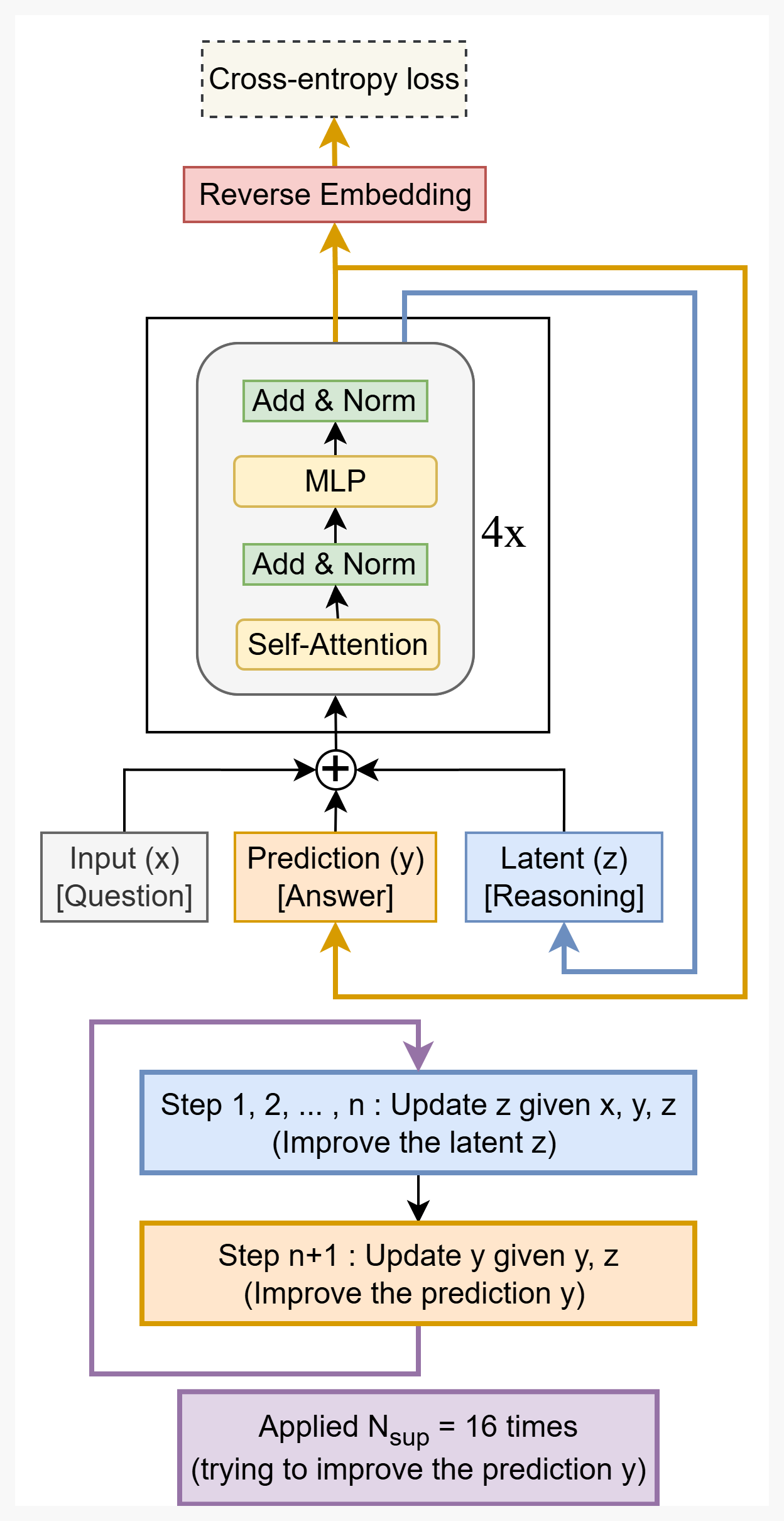
TRM의 핵심 구조는 위 다이어그램과 같다. 단일 네트워크가 입력 x, 현재 예측 y, 잠재 벡터 z를 받아 반복적으로 추론을 개선한다. Step 1~n에서는 z를 업데이트하고(잠재 추론), Step n+1에서는 y를 업데이트한다(예측 개선). 이 과정을 최대 N_sup = 16번 반복한다.
TRM은 HRM의 핵심 아이디어를 유지하면서 불필요한 복잡성을 하나씩 제거했다. 각 단순화는 Sudoku-Extreme 벤치마크로 검증됐다.
완전 역전파(Full Recursion Backpropagation)
HRM은 1단계 그래디언트 근사를 사용한다. TRM은 이 제약을 버리고 전체 재귀 과정에 역전파를 적용한다.
구체적으로 T-1번의 재귀 과정은 그래디언트 없이 잠재 상태를 개선하고, 마지막 1번의 재귀 과정에 완전한 역전파를 적용한다. 수학적 정리에 의존하지 않아도 되므로 설계가 단순해지고, 실험적으로도 성능이 크게 개선됐다.
이 변경만으로 Sudoku-Extreme 정확도가 **56.5% → 87.4%**로 30.9%p 향상됐다.
TRM 의사코드는 다음과 같다.
def latent_recursion(x, y, z, n=6):
for i in range(n): # 잠재 추론: z 업데이트
z = net(x, y, z)
y = net(y, z) # 예측 개선: y 업데이트
return y, z
def deep_recursion(x, y, z, n=6, T=3):
with torch.no_grad(): # T-1번: 그래디언트 없이 개선
for j in range(T - 1):
y, z = latent_recursion(x, y, z, n)
y, z = latent_recursion(x, y, z, n) # 마지막 1번: 완전 역전파
return (y.detach(), z.detach()), output_head(y), Q_head(y)
# 심층 감독(Deep Supervision) 학습 루프
for x_input, y_true in train_dataloader:
y, z = y_init, z_init
for step in range(N_supervision):
x = input_embedding(x_input)
(y, z), y_hat, q_hat = deep_recursion(x, y, z)
loss = softmax_cross_entropy(y_hat, y_true)
loss += binary_cross_entropy(q_hat, (y_hat == y_true))
loss.backward()
opt.step()
opt.zero_grad()
if q_hat > 0: # 조기 종료
break단일 네트워크 통합
HRM의 두 네트워크(f_H, f_L)를 하나로 통합했다. z와 y 업데이트가 공유하는 표현적 필요성이 크고, 입력 x의 유무만으로 두 작업을 자연스럽게 구분할 수 있기 때문이다.
파라미터는 27M → 13.5M으로 절반이 됐고, 정확도는 **82.4% → 87.4%**로 오히려 올랐다.
얕은 레이어 + 깊은 재귀
직관에 반하는 발견이다. 레이어 수를 4에서 2로 줄이고 재귀 횟수를 늘리면 정확도와 파라미터 효율이 모두 향상된다.
이유는 데이터 규모에 있다. 학습 데이터가 ~1,000개에 불과할 때, 큰 모델은 심각하게 과적합된다. 반면 초소형 네트워크는 재귀적 심층 감독이 암묵적 정규화 역할을 하여 일반화 성능을 높인다. 이는 deep equilibrium diffusion 모델에서 관찰된 현상과 맥을 같이 한다.
컨텍스트 크기에 따른 아키텍처 선택
9×9 스도쿠처럼 고정된 소형 컨텍스트에서는 self-attention을 MLP로 교체하면 파라미터를 줄이면서 정확도가 상승한다. 반면 ARC-AGI의 30×30 그리드처럼 가변 대형 컨텍스트에서는 self-attention이 여전히 우월하다.
MLP 전환으로 스도쿠 정확도 74.7% → 87.4% (+12.7%p)
간소화된 ACT
기존 Q-learning ACT에서 continue-loss를 제거하고, 단순한 이진 분류(정답에 도달했는가)만 남겼다. 두 번째 순전파가 사라져 연산이 절반으로 줄고, 정확도 손실은 미미하다.
**86.1% → 87.4%**로 오히려 소폭 향상.
Exponential Moving Average(EMA)
소규모 데이터셋에서 학습 안정성을 높이고 Catastrophic Forgetting을 방지하기 위해 EMA(계수 0.999)를 적용했다.
EMA 없이는 정확도 79.9%, EMA 추가 시 87.4% (+7.5%p)
최적 재귀 설정
경험적 탐색 결과 T=3, n=6 (유효 깊이 3×(6+1)×2 = 42레이어)이 스도쿠 최적으로 나타났다. HRM의 T=2, n=2(유효 깊이 24)는 충분하지 않았다. n이 6을 초과하면 수익 체감이 나타나 과도한 재귀는 최적화 난이도나 메모리 한계를 만든다.
절제 연구(Ablation Study)
각 설계 결정의 기여도를 Sudoku-Extreme에서 정량화한 결과다.
| 변경 사항 | 정확도 | 영향 |
|---|---|---|
| 완전한 TRM (T=3, n=6) | 87.4% | 기준 |
| + ACT (Q-learning) 추가 | 86.1% | -1.3% |
| f_H, f_L 분리 | 82.4% | -5.0% |
| EMA 제거 | 79.9% | -7.5% |
| 4레이어, n=3 | 79.5% | -7.9% |
| Self-attention 포함 | 74.7% | -12.7% |
| T=2, n=2 | 73.7% | -13.7% |
| 1단계 그래디언트 근사(HRM 방식) | 56.5% | -30.9% |
1단계 그래디언트 근사를 사용하면 30.9%p가 하락하는 것이 가장 두드러진다. 완전 역전파가 TRM 성능의 핵심임을 입증한다.
벤치마크 결과
TRM은 7M 파라미터 단일 네트워크로 경쟁 LLM들을 제치고 최고 성능을 달성했다.
| 벤치마크 | TRM (7M) | HRM (27M) | 최고 LLM |
|---|---|---|---|
| Sudoku-Extreme | 87.4% | 55.0% | 0.0% (DeepSeek R1) |
| Maze-Hard | 85.3% | 74.5% | 0.0% |
| ARC-AGI-1 | 44.6% | 40.3% | 37.0% (Gemini 2.5 Pro) |
| ARC-AGI-2 | 7.8% | 5.0% | 4.9% (Gemini 2.5 Pro) |
특히 ARC-AGI-2는 기존 어떤 모델도 5%를 넘지 못하던 난제다. TRM은 파라미터 수로는 경쟁 LLM의 0.01% 미만이면서 이를 달성했다.
학습 환경: Sudoku·Maze는 L40S GPU로 24시간, ARC-AGI는 H100 GPU로 최대 72시간 학습.
잠재 특징의 시각화
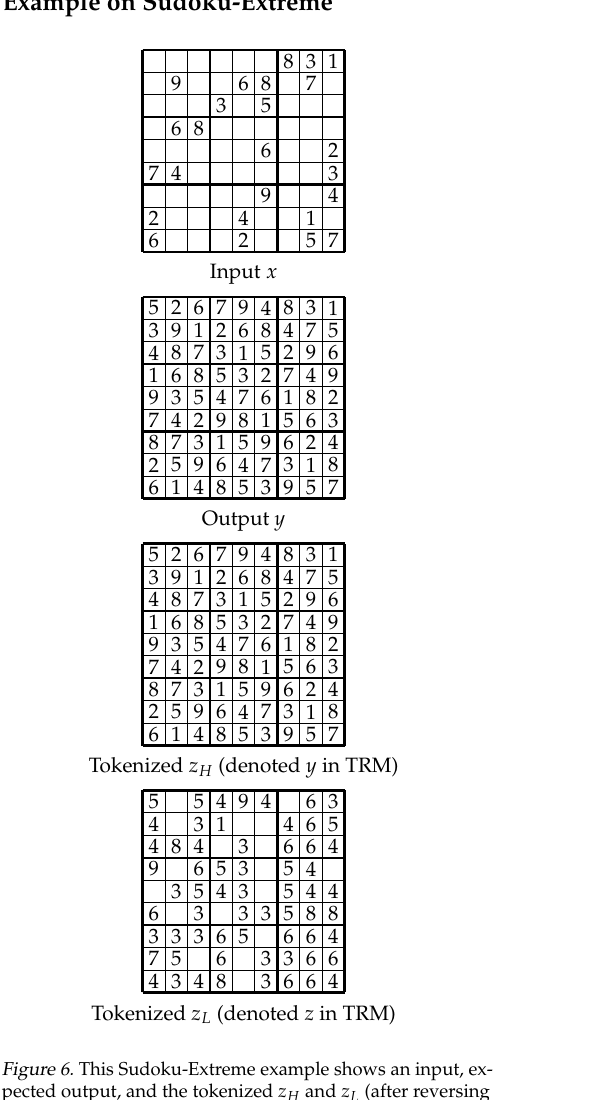
논문은 Sudoku-Extreme 예시를 통해 TRM의 두 잠재 특징이 어떻게 작동하는지 시각화한다. **y(예측에 대응)**는 임베딩을 역변환하면 실제 정답 격자와 거의 일치하는 반면, **z(추론에 대응)**는 의미 있는 Sudoku 숫자로 디코딩되지 않는다. z는 직접 읽히지 않는 순수 추론 공간이며, y 업데이트를 통해서만 해석 가능한 형태로 변환된다.
시도했지만 실패한 방법들
논문이 솔직하게 공개한 실패 사례들도 중요한 교훈을 준다.
- Mixture-of-Experts(MoE): 용량이 지나치게 늘어나 오히려 일반화 성능이 저하됐다.
- 부분 그래디언트 역전파: HRM의 2단계와 TRM의 완전 역전파 사이 중간점은 이점이 없었다.
- 고정점 반복(TorchDEQ): 학습이 느려질 뿐 성능 향상이 없었다.
- 임베딩·출력 가중치 공유: 모델 제약이 과도해 성능이 저하됐다.
왜 재귀가 스케일보다 효과적인가.
이 논문의 핵심 통찰은 데이터 효율성에 있다. 추론 과제는 방대한 학습 데이터가 없다. 이런 상황에서 모델을 크게 만들면 과적합의 덫에 빠진다.
반면 초소형 네트워크에 재귀적 심층 감독을 결합하면 암묵적 정규화 효과가 발생한다. 모델은 특정 예시를 암기하는 대신, 일반화 가능한 해결 절차를 학습하도록 압력을 받는다. 반복적인 자기 수정이 Chain-of-Thought의 수학적 구현에 해당하는 셈이다.
정리: "Less is More"의 의미.
TRM이 전달하는 메시지는 단순하다. 추론 과제에서 스케일이 항상 답은 아니다. 올바른 귀납적 편향(재귀적 추론, 심층 감독)과 적절한 정규화(EMA, 초소형 네트워크)가 결합될 때, 파라미터 수가 10,000배 적은 모델이 거대 LLM을 뛰어넘을 수 있다.
파라미터를 더 쌓기 전에, 구조를 단순하게 만드는 것이 먼저일 수 있다.
논문: Less is More: Recursive Reasoning with Tiny Networks (arXiv:2510.04871) 저자: Alexia Jolicoeur-Martineau (Samsung AI Lab Montreal)
AI 솔루션이 필요하신가요?
cortexys.ai에서 맞춤 AI 개발 서비스를 확인하세요.
![[논문] KoALa 한국어 음성 AI를 제대로 평가하는 최초의 종합 벤치마크](https://arxiv.org/html/2604.19782v1/images/K-Bench-A.png)
![[논문] 데이터가 적을 때 이미지 AI를 제대로 훈련하는 법 - APT기법](https://arxiv.org/html/2507.02687v1/x1.png)
![[KANANA429] Kanana-o 멀티모달 AI의 아키텍처와 서빙 구조](https://xnnnqymhqgwnvwuvbbrp.supabase.co/storage/v1/object/public/blog-images/thumbnails/1778320520390-snaphub_r5_6938.jpg________.jpg________.jpg)