NC AI 연구팀이 ACM CIKM 2025에 발표한 V-Agent를 분석합니다. VLM을 영상 검색 모델로 변환하는 Retrieval Vector 기법, 세 에이전트의 협력 구조, MultiVENT 2.0 SOTA 달성 과정을 수식과 실험 데이터로 상세히 분석합니다.
 Cortexys2026.01.14VLM영상 검색멀티에이전트RAG논문 분석Task ArithmeticCIKM 2025
Cortexys2026.01.14VLM영상 검색멀티에이전트RAG논문 분석Task ArithmeticCIKM 2025YouTube도 영상 내용을 이해 못한다 — VLM 기반 멀티에이전트 검색
"파란 셔츠를 입은 사람이 발표하는 영상 찾아줘" — YouTube는 이 쿼리를 제대로 처리하지 못한다.
영상 콘텐츠가 폭발적으로 증가하는 시대에, 검색 엔진들은 여전히 제목, 태그, 설명문 같은 텍스트 메타데이터에 의존합니다. 영상 속 시각 정보나 음성을 직접 이해하는 능력은 없습니다.
NC AI(NC소프트 AI 연구소)의 연구팀이 ACM CIKM 2025에서 발표한 V-Agent는 이 문제를 세 가지 협력 AI 에이전트와 새로운 VLM 파인튜닝 기법으로 해결합니다. MultiVENT 2.0 벤치마크에서 기존 최고 모델을 9.4%p 이상 앞선 SOTA를 달성했습니다.
기존 방법의 한계

현재 영상 검색의 문제점은 크게 두 가지입니다.
1. 텍스트 메타데이터 의존 YouTube와 Google Video는 영상의 시각·음성 콘텐츠를 직접 분석하지 않습니다. 검색 품질은 콘텐츠 제작자가 얼마나 좋은 제목/태그/설명을 달았는지에 달려 있습니다.
2. 기존 VLM의 검색 능력 부족 GPT-4o나 Qwen2-VL 같은 강력한 Vision-Language Model(VLM)들은 영상 이해 능력이 탁월하지만, 텍스트-영상 검색 특화 훈련이 되어 있지 않아 검색 태스크에서 극히 낮은 성능을 보입니다.
실제로 논문의 실험에서 Qwen2-VL-7B-Instruct를 검색 모델로 사용하면 MSR-VTT에서 R@1 = 0.002라는 처참한 성능이 나옵니다.
V-Agent 시스템 개요
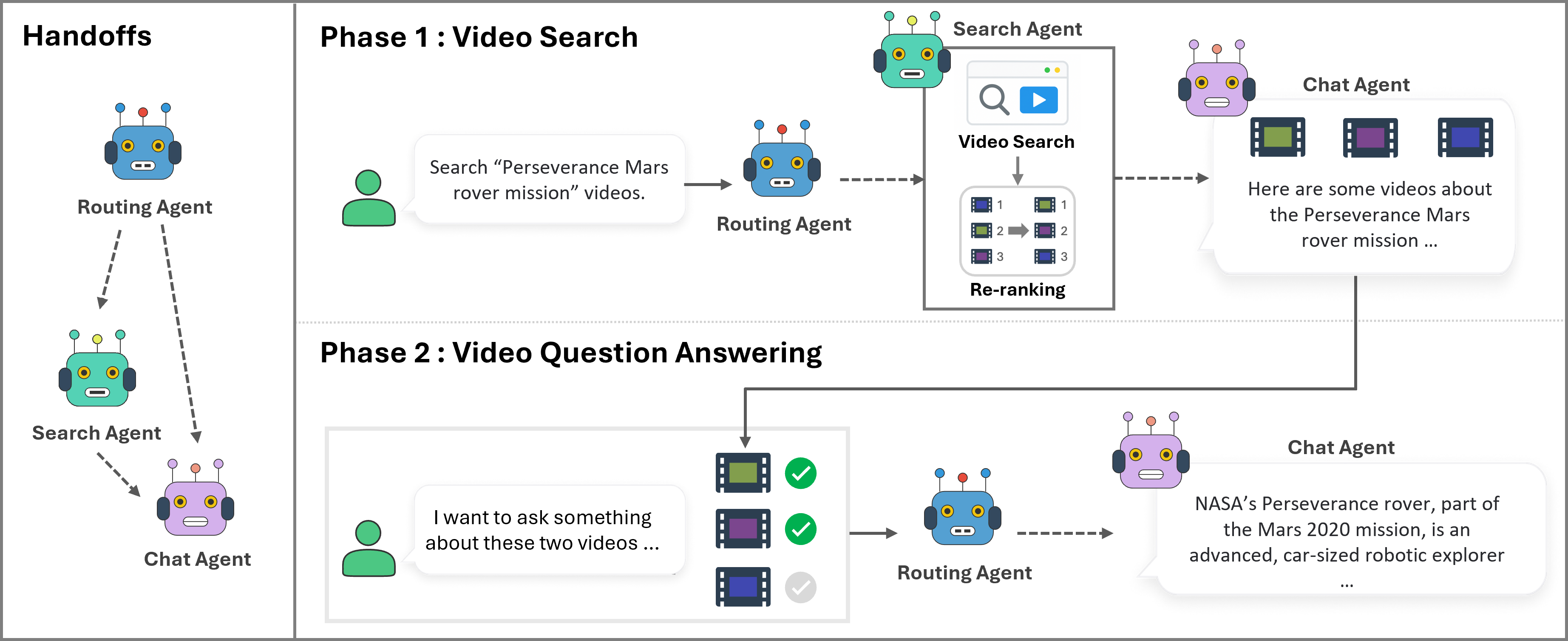
V-Agent는 세 가지 에이전트가 협력하는 구조입니다.
| 에이전트 | 모델 | 역할 |
|---|---|---|
| 라우팅 에이전트 | gpt-4.1-mini | 쿼리 의도 파악 → 검색 vs. 대화 분기 |
| 검색 에이전트 | gpt-4o | 영상 검색 + LLM 기반 재순위화 |
| 채팅 에이전트 | gpt-4o | 검색 결과 기반 대화형 응답 생성 |
이 세 에이전트를 가능하게 하는 핵심은 영상-텍스트 검색 모델 입니다. 이 모델을 어떻게 만드는지가 논문의 핵심 기여입니다.
핵심 기술 1: 비디오-텍스트 검색 모델
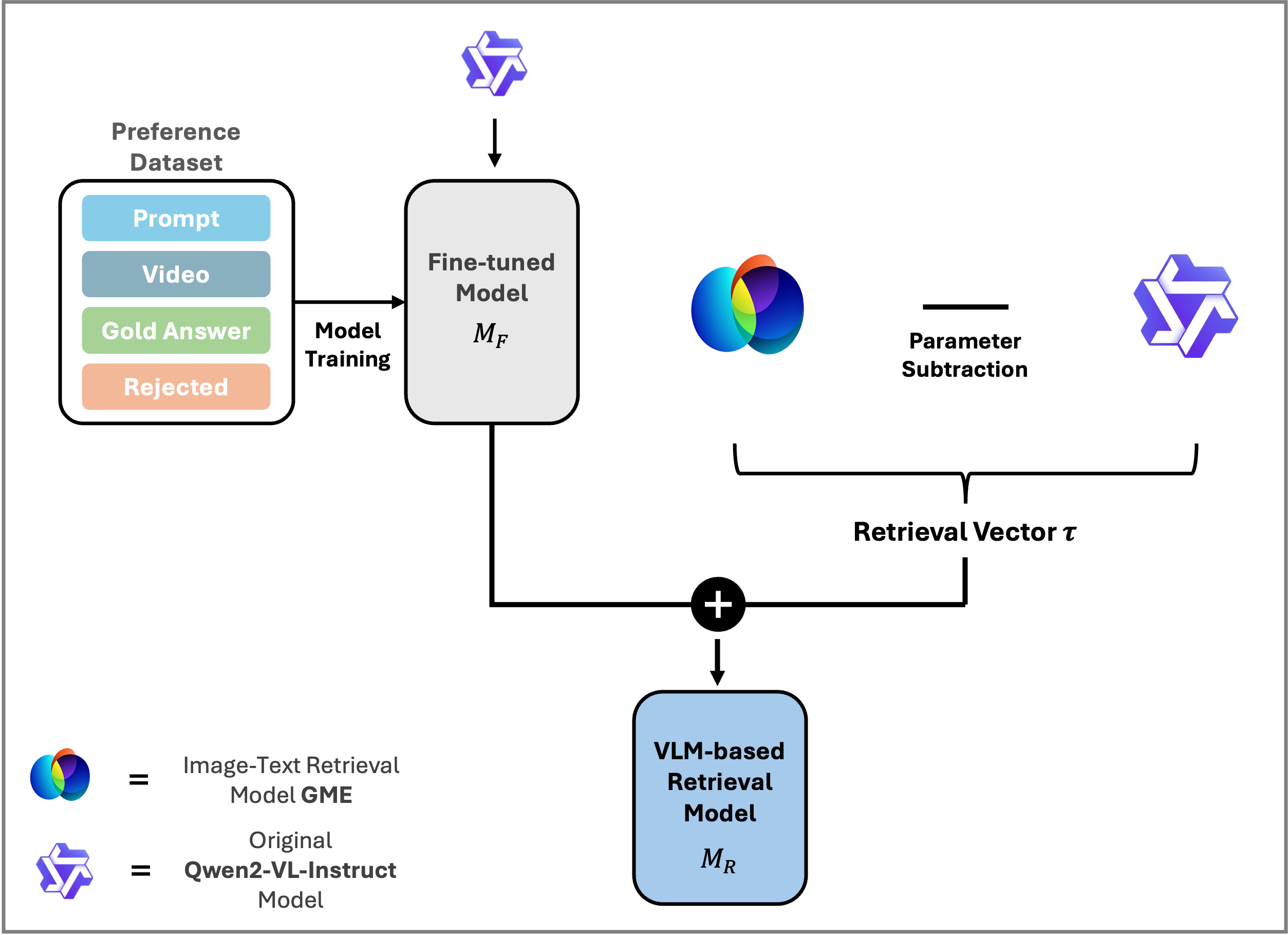
Qwen2-VL-7B-Instruct라는 일반 VLM을 영상 검색 특화 모델로 변환하는 과정은 두 단계로 이루어집니다.
Step 1: 비디오 선호도 데이터셋으로 파인튜닝
ShareGPTVideo의 17K 비디오 선호도 데이터셋을 사용합니다. 각 데이터 샘플은.
- : 시스템/사용자 프롬프트 + 영상 (쿼리)
- : 정답 응답 (positive)
- : 기각 응답 (hard negative)
모델은 쿼리와 응답들을 각각 EOS 토큰의 마지막 히든 스테이트로 임베딩합니다.
학습 손실로는 in-batch negative + 1개의 hard negative를 결합한 InfoNCE를 사용합니다.
- 8× A100 GPU, 배치 크기 8, 2 에포크
- 훈련 시간: 몇 시간 수준 (매우 효율적)
17K개라는 적은 데이터로 전체 파인튜닝(full fine-tuning)을 진행하기 때문에, 이미지-텍스트 검색 능력이 충분히 학습되지 않을 수 있습니다. 이를 해결하는 것이 다음 단계입니다.
Step 2: 검색 벡터(Retrieval Vector) 추가 — 가장 독창적인 기여
논문의 핵심 아이디어입니다. GME(General Multimodal Embeddings) 라는 Qwen2-VL 기반의 이미지-텍스트 검색 모델에서 학습된 검색 능력을 가중치 차이(weight difference) 형태로 추출합니다.
이 를 검색 벡터(Retrieval Vector) 라 부릅니다. 이를 파인튜닝된 모델에 더합니다.
왜 이 방법이 동작하는가?
이 아이디어는 Task Arithmetic 연구에서 영감을 받았습니다. 어떤 능력의 차이를 모델 가중치 차이로 표현할 수 있다면, 그 차이를 다른 모델에 더해 해당 능력을 이식할 수 있다는 개념입니다.
구체적으로.
- 은 "원본 Qwen2-VL에 검색 능력을 더하기 위해 필요한 가중치 변화"를 나타냅니다
- 이것을 비디오 파인튜닝된 에 더하면 → 비디오 이해 + 검색 능력을 동시에 갖는 모델
쉽게 말하면: "이미 학습된 검색 전문가의 지식을 복사해서 영상 이해 모델에 붙여넣기" 하는 방식입니다. 추가 학습 없이, 가중치 덧셈 한 번으로.
핵심 기술 2: 비디오 검색 파이프라인
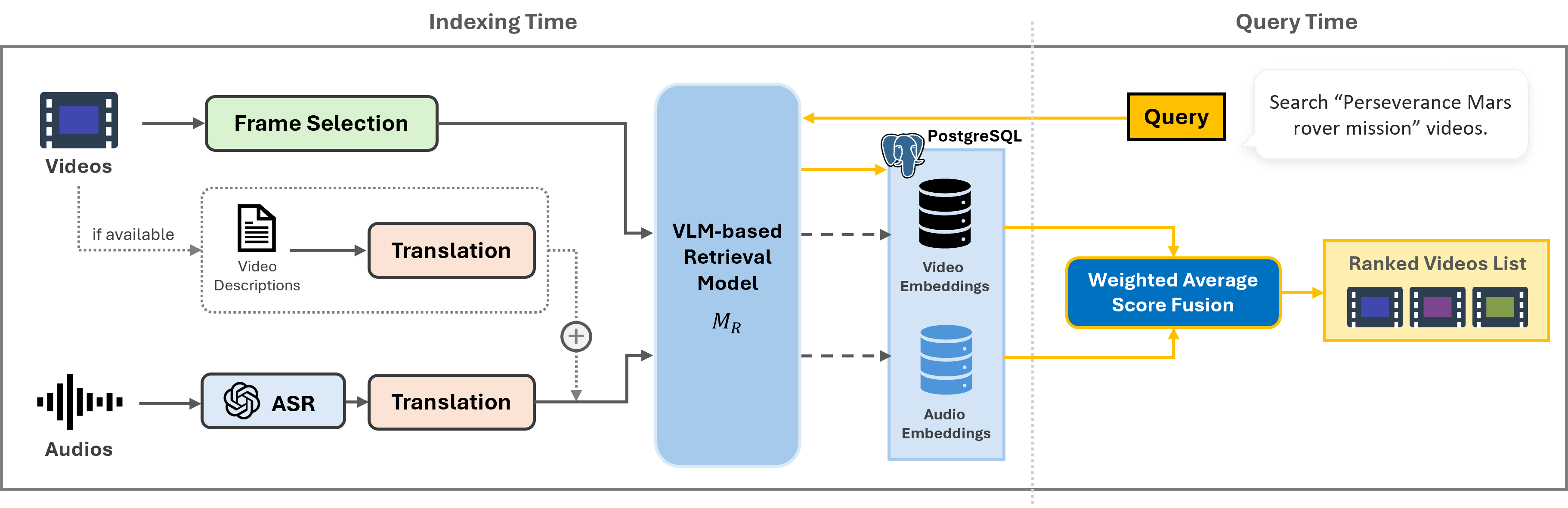
인덱싱 단계 (Indexing Time)
영상 데이터베이스를 사전에 처리하는 단계입니다.
- 음성 전사: OpenAI Whisper로 음성 → 텍스트 변환
- 설명문 준비: 기존 영상 설명(description) + 전사 텍스트 결합, 비영어 텍스트는 gpt-4o-mini로 영어 번역
- 프레임 추출: 영상당 48프레임을 균일 간격으로 추출
- 임베딩: 로 프레임 임베딩()과 음성 텍스트 임베딩() 생성
- 벡터 인덱싱: pgvector + HNSW (m=16, ef_construction=200) 설정으로 저장
쿼리 단계 (Query Time)
사용자 쿼리가 들어오면.
영상별 최종 점수는 시각·음성 점수의 가중 평균.
비주얼 프레임과 음성 텍스트를 같은 임베딩 공간에 함께 인덱싱한다는 점이 특징입니다. MMMORRF처럼 모달리티별로 별도 모델을 쓰지 않고, 단일 모델로 통합 처리합니다.
에이전트 파이프라인
라우팅 에이전트 (gpt-4.1-mini)
쿼리의 의도를 파악해서 분기합니다.
저렴한 gpt-4.1-mini를 쓰는 이유: 라우팅은 복잡한 추론이 아닌 의도 분류 태스크라 경량 모델로 충분합니다.
검색 에이전트 (gpt-4o + gpt-4o-mini)
두 단계로 동작합니다.
Step 1 — 벡터 검색:
각 후보 영상은 음성 전사와 텍스트 설명 쌍으로 표현됩니다.
Step 2 — LLM 기반 재순위화 (gpt-4o-mini):
상위 개 결과를 LLM으로 재순위화합니다. 텍스트(음성 전사 + 설명)만으로 재순위화하는 것이 현재 한계 — 논문에서도 시각 정보 통합이 향후 과제임을 인정합니다.
채팅 에이전트 (gpt-4o)
사용자가 영상을 선택하면 해당 영상의 음성 전사 + 설명을 컨텍스트로 사용해 질의응답을 생성합니다.
실험 결과
MSR-VTT 벤치마크 (Text-to-Video 검색)
MSR-VTT: 10,000개 영상, 영상당 5개 캡션, 1K 테스트 셋
| 모델 | R@1 | R@5 | R@10 |
|---|---|---|---|
| Qwen2-VL-7B-Instruct (프롬프팅만) | 0.002 | 0.006 | 0.010 |
| GME-7B (Mean Pooling) | 0.411 | 0.655 | 0.764 |
| GME-7B (Multi-image) | 0.201 | 0.383 | 0.485 |
| LamRA | 0.447 | 0.686 | 0.786 |
| InternVideo2-6B | 0.559 | 0.783 | 0.851 |
| M_F (파인튜닝만) | 0.413 | 0.661 | 0.750 |
| M_R (검색 벡터 추가) | 0.476 | 0.720 | 0.798 |
Qwen2-VL의 R@1 = 0.002라는 수치는 프롬프팅만으로는 일반 VLM을 검색 모델로 쓸 수 없다는 것을 명확히 보여줍니다. InternVideo2가 MSR-VTT에서 최고 성능이지만, 다음 벤치마크에서 반전이 일어납니다.
MultiVENT 2.0 벤치마크 (핵심 승부처)
MultiVENT 2.0: 6개 언어(아랍어, 중국어, 영어, 한국어, 러시아어, 스페인어), 3,900개 쿼리, 109,800개 영상. 시각·음성·자막·메타데이터를 모두 활용해야 하는 현실적인 어려운 벤치마크.
| 모델 | nDCG@10 | R@10 |
|---|---|---|
| InternVideo2-6B | 0.005 | 0.004 |
| VAST | 0.116 | 0.118 |
| CLIP | 0.304 | 0.333 |
| LanguageBind | 0.324 | 0.355 |
| SigLIP | 0.375 | 0.409 |
| MMMORRF | 0.586 | 0.611 |
| V-Agent (Ours) | 0.680 | 0.676 |
V-Agent는 nDCG@10에서 기존 SOTA(MMMORRF)를 9.4%p 격차로 능가합니다.
InternVideo2의 역전이 흥미롭습니다: MSR-VTT에서 1등(R@1 = 0.559)이었던 모델이 MultiVENT 2.0에서 꼴찌(nDCG@10 = 0.005)가 됩니다. 이유는 두 가지.
- MultiVENT 2.0은 낮은 품질의 캡션을 가진 영상이 많아서 단순 캡션 기반 모델이 실패
- 다국어 쿼리와 복잡한 이벤트 중심 검색은 대규모 비디오 파운데이션 모델에서도 어려운 태스크
어블레이션 분석: 무엇이 성능을 만드는가
| 모델 | 프레임 수 | 검색 벡터 | 영상 설명 | 재순위화 | nDCG@10 | R@10 |
|---|---|---|---|---|---|---|
| V-Agent (Full) | 48 | ✓ | ✓ | ✓ | 0.680 | 0.676 |
| 32 | ✓ | ✓ | ✓ | 0.675 | 0.671 | |
| 재순위화 제거 | 48 | ✓ | ✓ | ✗ | 0.614 | 0.676 |
| 32 | ✓ | ✓ | ✗ | 0.611 | 0.671 | |
| 16 | ✓ | ✓ | ✗ | 0.607 | 0.671 | |
| 검색 벡터 제거 | 16 | ✗ | ✓ | ✗ | 0.597 | 0.660 |
| 설명문 제거 | 16 | ✓ | ✗ | ✗ | 0.518 | 0.587 |
| 둘 다 제거 | 16 | ✗ | ✗ | ✗ | 0.509 | 0.573 |
발견 1: 재순위화가 nDCG에 가장 큰 기여 (+6.6%p)
재순위화를 제거하면 nDCG@10이 0.680 → 0.614로 급락합니다. 반면 R@10은 변화 없습니다(0.676 유지). 이 패턴이 의미하는 바.
- R@10: "상위 10개 중 정답이 있는가" → 벡터 검색 자체가 충분히 잘 찾음
- nDCG@10: "정답이 얼마나 상위에 있는가" → 순위 정밀도는 LLM 재순위화가 결정적
즉 은 정답 영상을 상위 10개 안에 잘 가져오고, LLM이 그 순서를 정밀하게 재배열합니다.
발견 2: 영상 설명문이 핵심 자원 (설명 제거 시 -10.3%p)
영상 설명문을 제거하면 nDCG@10이 0.607 → 0.518로 크게 하락합니다. 검색 벡터 제거(0.607 → 0.597, -1%p)보다 훨씬 큰 영향입니다.
이는 두 가지를 시사합니다.
- MultiVENT 2.0에서 영상의 메타데이터 설명문은 시각 정보보다 검색에 더 직접적으로 기여
- 콘텐츠 설명 생성(VLM으로 자동 캡셔닝)이 검색 품질 향상의 핵심 레버리지 포인트
발견 3: 프레임 수는 점진적 향상 (16→48: +1.3%p)
16, 32, 48 프레임을 비교하면 차이가 크지 않습니다. 이는 균일 샘플링된 48프레임이 일종의 수익 체감(diminishing returns)에 진입했다는 신호입니다. 더 스마트한 프레임 선택(중요 장면 감지 등)이 필요할 수 있습니다.
발견 4: 검색 벡터 단독 효과는 제한적 (+1%p)
검색 벡터 추가 자체의 효과는 작지만(0.597 → 0.607), 비용이 거의 없는 기법임을 고려하면 포함할 가치가 있습니다.
실제 사용 사례
V-Agent는 두 가지 상호작용 모드를 지원합니다.
1. 검색 모드 (Search Mode)
- 사용자: "화성 탐사 로버 Perseverance 임무"
- 시스템: 관련 영상 목록 반환
2. 에이전트 모드 (Agent Mode)
- 시스템이 검색 결과와 함께 각 영상의 요약 제공
- 사용자가 영상 선택 후 질의응답
- 복수 영상 선택 → 여러 영상에 걸친 통합 질의응답 가능
에이전트 모드에서는 채팅 에이전트가 선택된 영상들의 음성 전사와 설명을 컨텍스트로 받아 답변을 생성합니다. 단순 검색을 넘어 영상 기반 대화형 인터페이스로 발전하는 것입니다.
기술 스택 정리
| 구성요소 | 기술 |
|---|---|
| 기반 VLM | Qwen2-VL-7B-Instruct |
| 이미지-텍스트 검색 모델 (검색 벡터 소스) | GME (Qwen2-VL 기반) |
| 파인튜닝 데이터 | ShareGPTVideo 17K 선호도 데이터 |
| 파인튜닝 프레임워크 | LLaMA-Factory |
| 음성 전사 | OpenAI Whisper |
| 번역 | gpt-4o-mini |
| 벡터 저장 | pgvector (HNSW, m=16, ef_construction=200) |
| 에이전트 오케스트레이션 | OpenAI Agents SDK |
| 라우팅 에이전트 | gpt-4.1-mini |
| 검색·채팅 에이전트 | gpt-4o |
| 재순위화 | gpt-4o-mini |
한계
논문이 인정하는 현재 한계.
1. 재순위화에서 시각 정보 미활용 현재 LLM 재순위화는 음성 전사 + 설명 텍스트만 사용합니다. 실제 영상 프레임 이미지를 LLM에 제공하면 더 정확한 순위화가 가능할 것으로 예상됩니다.
2. 에이전트 파이프라인 레이턴시 단순 벡터 검색보다 라우팅→검색→재순위화→채팅의 다단계 파이프라인이 응답 시간이 깁니다. 스트리밍 LLM 응답으로 사용자 체감 지연을 줄이는 방안을 검토 중입니다.
3. 비디오 내용 이해의 깊이 현재 채팅 에이전트는 음성 전사와 설명 텍스트에 의존합니다. 영상 프레임을 직접 LLM에 제공해 시각적 내용을 깊이 이해하는 방향이 자연스러운 발전입니다.
핵심 인사이트 요약
V-Agent가 중요한 이유:
-
현실적 문제 해결: YouTube와 같은 대규모 영상 플랫폼이 아직 해결 못 한 "시맨틱 영상 검색"을 실용적 시스템으로 구현
-
검색 벡터(Task Arithmetic) 기법: 대규모 영상-텍스트 쌍 없이도 기존 이미지-텍스트 검색 모델의 지식을 가중치 연산으로 이식. 훈련 없이 능력을 복사한다는 개념
-
멀티에이전트로 역할 분리: 라우팅/검색/채팅을 각각 최적 모델로 담당하여 품질-비용 균형을 세밀하게 제어
-
단일 모델로 멀티모달 통합: 시각 프레임과 음성 텍스트를 같은 임베딩 공간에 인덱싱해 별도 모달리티 파이프라인 없이 통합 처리
-
영상 설명문의 중요성 재확인: 어블레이션 결과, 자동 캡셔닝/설명 생성이 검색 품질에 결정적 영향. VLM 기반 자동 설명 생성 → 검색 파이프라인의 구성이 실용적 가치가 높음
마치며
V-Agent는 "검색 + 이해 + 대화"를 하나의 시스템으로 통합한 실용적 연구입니다. 학술적 실험을 넘어 실제 서비스로 배포 가능한 구조를 갖추고 있습니다.
특히 검색 벡터(Retrieval Vector) 라는 기법은 앞으로 더 많은 도메인에 응용될 가능성이 있습니다. 어떤 전문 능력을 가진 모델의 가중치 차이를 다른 모델에 이식하는 아이디어는 추론, 코드 생성, 수학 등 다양한 영역에 확장될 수 있습니다.
한국 AI 연구의 성과가 CIKM 같은 국제 무대에서 SOTA를 달성하고 있다는 점도 주목할 만합니다.
논문: V-Agent: An Interactive Video Search System Using Vision-Language Models
모델 및 데모: huggingface.co/NCSOFT/multimodal-embedding
AI 솔루션이 필요하신가요?
cortexys.ai에서 맞춤 AI 개발 서비스를 확인하세요.
![[논문] KoALa 한국어 음성 AI를 제대로 평가하는 최초의 종합 벤치마크](https://arxiv.org/html/2604.19782v1/images/K-Bench-A.png)
![[논문] 데이터가 적을 때 이미지 AI를 제대로 훈련하는 법 - APT기법](https://arxiv.org/html/2507.02687v1/x1.png)